AI Periodic Table: una forma simple de ordenar la IA en banca y fintech
Los pilotos fallan en producción cuando no existe un mapa claro entre conocimiento, orquestación, validación y modelos.
DISCLAIMER: Todo proyecto, y más uno de IA, debe tener objetivos claros y un proceso ágil de incepción correcto. Más aún, en temas de IA, el no tener claridad del ¿qué?, el ¿cómo? y las métricas de éxito van a derivav en frustación y proyectos fallidos.
La AI Periodic Table, creado por IBM, es un enfoque evergreen y minimalista para arquitectos, jefes y líderes técnicos: separa la solución en elementos composables (como una tabla periódica) y te ayuda a decidir qué necesitas para cada caso de uso (chatbot, RAG, agente) con control, trazabilidad y confianza.
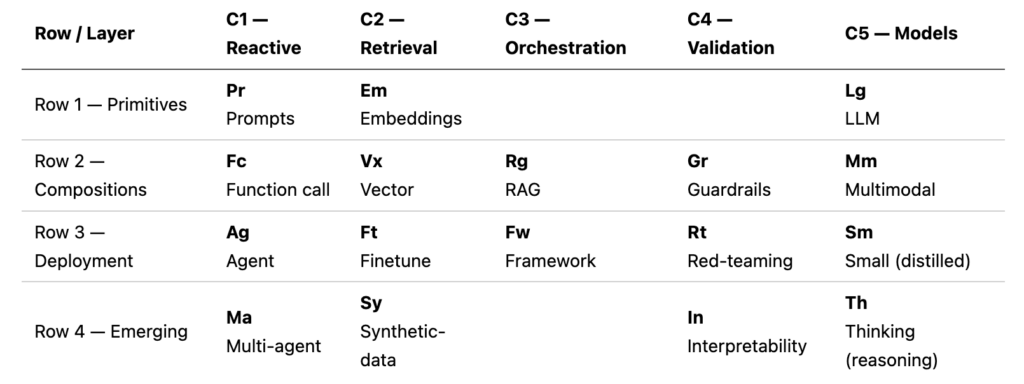
Row 1 — Primitives (lo mínimo que debe existir)
Pr — Prompts (con foco en system prompt)
Qué es: el diseño de instrucciones que gobiernan el comportamiento del modelo. En particular, el system prompt define rol, políticas, restricciones, formato, prioridades y criterio de “verdad”. Es la capa que siempre aplica, incluso si el usuario intenta desviarla.
Ejemplo (banca/fintech): system prompt para un asistente interno de pagos:
- “Responde solo usando evidencia del contexto recuperado. Si no hay evidencia, di: No encontrado en fuentes.”
- “No reveles PII, secretos, llaves, credenciales ni datos de clientes.”
- “No ejecutes acciones; sugiere pasos y valida supuestos.”
- “Devuelve: Resumen (1–2 líneas) + Evidencia (citas) + Recomendación (pasos).”
Em — Embeddings
Qué es: representaciones numéricas del significado del texto (y a veces de otros formatos) para comparar similitud semántica y recuperar conocimiento relevante.
Ejemplo: embebes runbooks de conciliación y reglas ISO 20022. Luego consultas “cómo mapear endToEndId” y recuperas el fragmento correcto aunque el usuario use otras palabras.
Lg — LLM (modelo predictivo)
Qué es: un modelo de lenguaje es, en esencia, un modelo predictivo de tokens: estima el siguiente token más probable dada la entrada (system prompt + contexto recuperado + conversación). Con el contexto correcto, habilita síntesis, explicación, clasificación y razonamiento.
Ejemplo (open source): usas un LLM open source como Llama 3 (en una VPC o en entorno local) para resumir incidentes, generar borradores operativos y responder preguntas internas basadas en evidencia (vía RAG) y bajo políticas (guardrails).
Row 2 — Compositions (cuando pasa de demo a producto)
Fc — Function call
Qué es: un mecanismo para invocar herramientas (APIs, DB, motores de reglas) con parámetros estructurados. Reduce “inventos” porque los datos vienen del sistema fuente.
Ejemplo: “¿Cuál fue el estado del lote 7781?” → llamada a get_settlement_batch_status(batch_id=7781) y respuesta con estado real, timestamps y códigos.
Vx — Vector (vector store / vector search)
Qué es: la infraestructura para almacenar embeddings y hacer búsqueda semántica (kNN). Es el índice de conocimiento para recuperar contexto.
Ejemplo: OpenSearch Vector indexa manuales antifraude, catálogos de códigos y procedimientos. Para cada pregunta, recuperas “top 5 chunks” con score y los pasas a RAG.
Rg — RAG
Qué es: patrón de recuperar + generar: primero recuperas evidencia desde tu base documental (vector o híbrido) y luego el LLM genera respuesta basándose en esa evidencia.
Ejemplo: “¿Qué campos ISO 20022 son obligatorios para pacs.008 en nuestro flujo?” → recuperas el apartado exacto de tu estándar interno y respondes con lista + citas.
Gr — Guardrails
Qué es: controles de seguridad y calidad: políticas (PII/secretos), límites de herramientas, formatos obligatorios, detección de inyección, y rechazo seguro.
Ejemplo: si el usuario solicita datos de cliente, se bloquea. Si la respuesta no tiene evidencia, se fuerza: “No encontrado en fuentes”.
Mm — Multimodal
Qué es: capacidad para trabajar con más de texto (por ejemplo, imagen + texto). Útil para diagramas, capturas, formularios y pantallazos.
Ejemplo: un analista sube una captura de un diagrama de pagos y el sistema devuelve componentes, flujo, puntos de control y sugerencias de observabilidad.
Row 3 — Deployment (operación real: costo, riesgo y mejora continua)
Ag — Agent (componente, no un LLM)
Qué es: un componente de control que coordina pasos para lograr un objetivo. El agente usa uno o varios LLMs, herramientas y memoria, pero no es el modelo. Decide cuándo recuperar contexto, cuándo llamar herramientas, cómo validar y cuándo detenerse.
Ejemplo: “resolver un incidente de conciliación” → el agente identifica el fallo, recupera runbooks (RAG), ejecuta chequeos (function calls), valida hallazgos y produce un plan de mitigación trazable.
Ft — Finetune (entrenamiento adicional)
Qué es: entrenar (fine-tuning) un modelo con datos propios para aprender patrones de salida, taxonomías, formatos o decisiones recurrentes. Es especialmente útil cuando prompt + RAG no logran consistencia suficiente.
Ejemplo: entrenas para que el asistente clasifique tickets en categorías internas (riesgo, fraude, cumplimiento), y redacte respuestas en un formato de auditoría consistente.
Fw — Framework
Qué es: librerías para construir flujos con control (estados, routing, tools, memoria, evaluación, observabilidad). Reduce código “pegamento” y mejora mantenibilidad.
Ejemplo: defines un flujo: intención → retrieve → responder → (si pide acción) tool_call → validar → respuesta final con reintentos y límites por política.
Rt — Red-teaming
Qué es: pruebas adversarias para romper el sistema antes de producción: jailbreak, prompt injection, exfiltración, abuso de herramientas y sesgos.
Ejemplo: inyectas instrucciones maliciosas en documentos (“ignora políticas”) y verificas que el sistema no obedezca; también pruebas pedidos de acciones riesgosas y confirmas que no se ejecutan sin autorización y controles.
Sm — Small (distilled)
Qué es: modelos pequeños para tareas específicas con menor costo/latencia; permiten enrutar y filtrar, reservando el modelo grande para lo complejo.
Ejemplo: un modelo small clasifica intención (FAQ/operación/incidente/riesgo) y solo las complejas pasan a LLM grande + RAG.
Row 4 — Emerging (calidad, confianza y ventaja competitiva)
Ma — Multi-agent
Qué es: varios agentes especializados que colaboran y revisan. Aumentan calidad y reducen errores frente a una sola “mente”.
Ejemplo: agente de pagos redacta, agente de seguridad valida PII, agente de compliance revisa lenguaje regulatorio, agente QA verifica evidencia y consistencia.
Sy — Synthetic data
Qué es: datos sintéticos para entrenamiento y evaluación: casos borde, Q&A, conversaciones, escenarios raros. Permite escalar pruebas sin exponer data sensible.
Ejemplo: generas 2,000 preguntas sintéticas sobre AML y conciliación para medir recuperación correcta, tasa de alucinación y cumplimiento de guardrails.
In — Interpretability (confianza y trazabilidad)
Qué es: mecanismos que elevan confianza y auditabilidad: qué fuentes se usaron, por qué se eligieron, qué reglas se aplicaron y qué herramientas se llamaron. Es clave para operación en entornos regulados.
Ejemplo: cada respuesta incluye “fuentes (con score)”, “reglas aplicadas” y “acciones ejecutadas (si aplica)”, habilitando revisión y mejora continua.
Th — Thinking (reasoning)
Qué es: capacidades/modelos orientados a razonamiento profundo para problemas multi-paso y trade-offs.
Ejemplo: compara 3 diseños (multi-cuenta vs multi-región), evalúa seguridad, resiliencia y costos, y entrega recomendación con supuestos y justificación.
Analogía final: “predecir reacciones” con la AI Periodic Table
Esta tabla te ayuda a anticipar qué solución obtendrás al combinar elementos.
Reacción 1: Chatbot confiable (con evidencia y control)
help to predict reactions
chatbot: Em, Vx, Rg, Pr, Gr y Lg
- Em + Vx: recuperación semántica
- Rg: evidencia al contexto del modelo
- Pr: reglas globales (system prompt)
- Gr: seguridad/calidad
- Lg: generación predictiva guiada por evidencia
Reacción 2: Agentic loop orientado a objetivo (con acciones)
agentic loop (goal): Ag <-> Fc, Fw [Pr, Mm, Ft, Lg]
- Ag coordina pasos
- Fc conecta con sistemas reales
- Fw gobierna el flujo
- Pr/Mm/Ft/Lg ajustan comportamiento, entrada multimodal, entrenamiento y potencia del modelo
Regla de oro
always try to mapping you problem with it
Antes de elegir proveedor o modelo, mapea tu problema con la tabla: te dirá qué necesitas para evidencia, control, operación y confianza, sin perderte.
IBM es el creador de esta propuesta mira acá:

